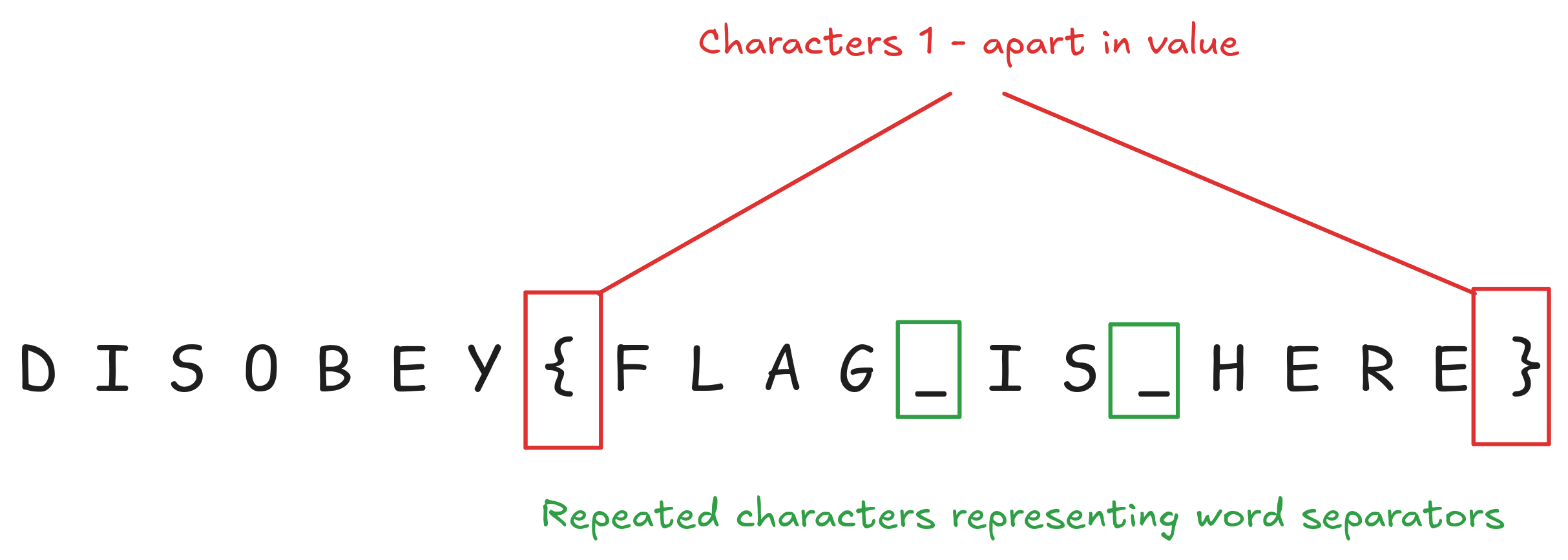
In Feburary last year I attended Disobey in Finlandhttps://disobey.fi/2025/ , it was a great event, although very cold. At the event was a good CTF, with a bunch of physical challenges that were hosted in the building. I didn't spend too much time in the CTF, but in this post I'm going to write up my failed attempt to solve one of the challenges.
I didn't solve this at the event, just downloaded the capture file, and later took a look. As such, I didn't have the original challenge name, the description, or any other supporting files. All I had was this one file: capture.complex16. This was also my first time diving into practical signal analysis and radio hacking, so was a learning journey.
Radio basics
First off, it may be helpful to quickly familiarise yourself with the basics of radio signals:
Radio signals are transmitted via Sine waves in the RF spectrum. At a given point in time we can measure the FREQUENCY at which the wave oscillates, and the AMPLITUDE, or signal strength, of waves, using an antenna.
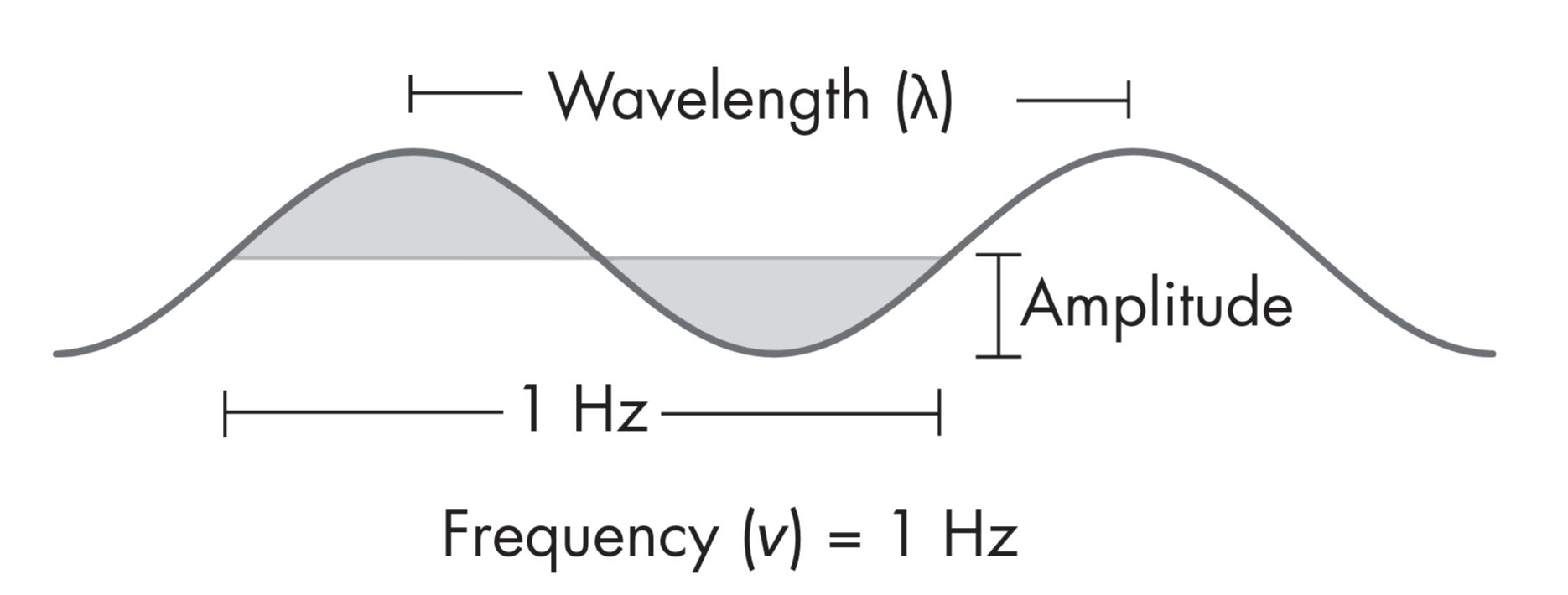
From The Wireless Cookbook, figure 1-1
We communicate
information by encoding the information into 1's and 0's, and then super-imposing this onto a sine wave. The wave without information is known as a carrier frequency, and the act of super-imposing of information onto a carrier is known as MODULATION. There are multiple forms of modulation:
- changing the Amplitude over time: this is known as Amplitude modulation (AM). AM of 1's and 0's is known as Amplitude Shift Keying (ASK).
- changing the Frequency over time: this is known as Frequency modulation (AM). AM of 1's and 0's is known as Frequency Shift Keying (FSK).
- changing the "phase" of the sine wave: this is known as Phase Shift Keying (PSK)
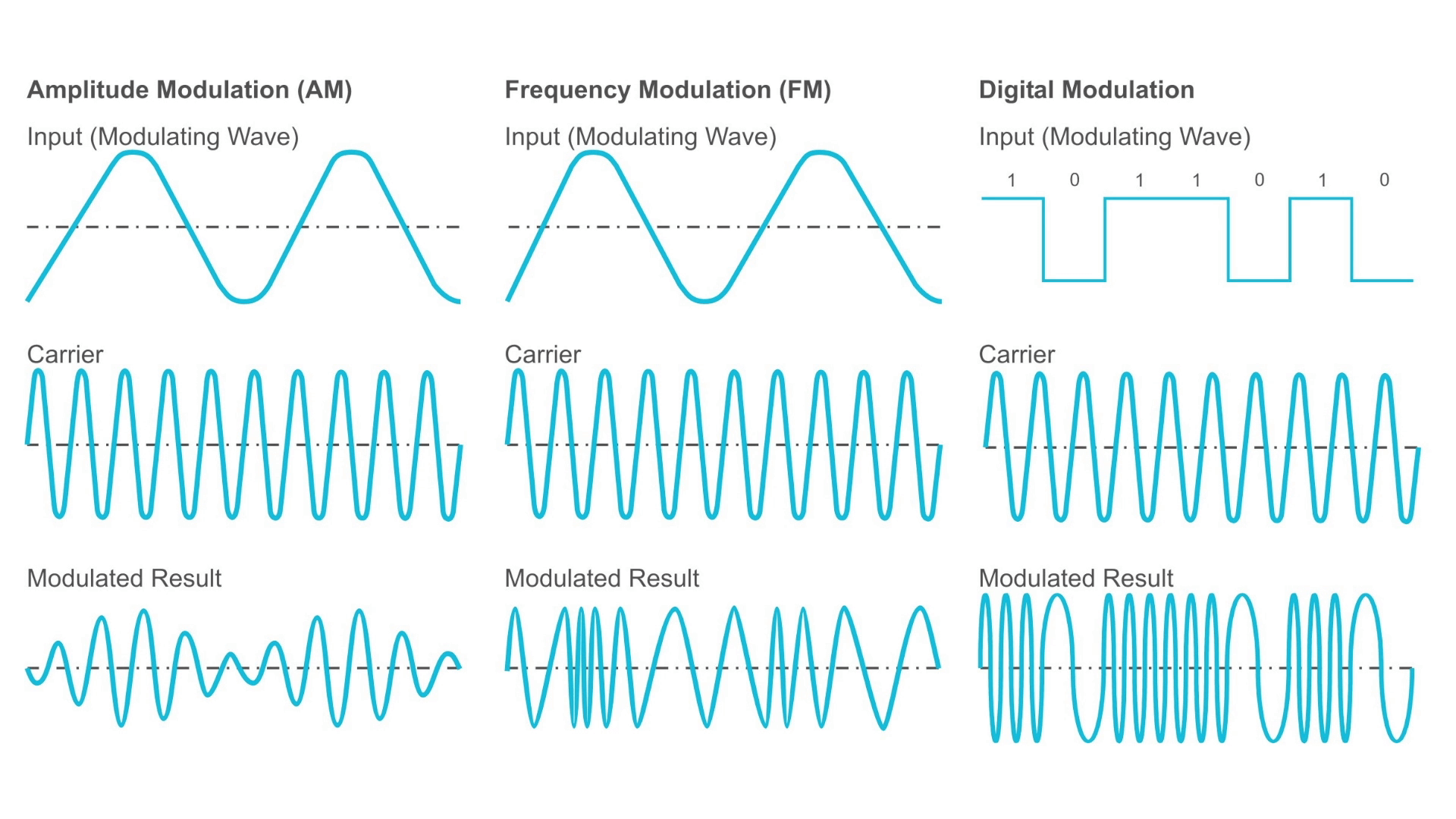
This diagram shows FSK as "Digital Modulation"
To retrieve information from a radio signal, we simply perform this process in reverse:
- we recieve the signal with an antenna, and do some horrible maths to recover the frequencies it contains
- we identify and isolate a particular signal within the data (A frequency range containing a signal is referred to as a BAND or CHANNEL)
- we DE-modulate the signal to recover 1's and 0's
- we deconstruct the protocol and decode the data to recover the original information
At some point we may need to perform some decryption as well, depending on the protocol.
This is what we are going to do for this challenge: we have a captured signal, and will deconstruct it to find the original information (a flag).
Loading the file
The challenge gives us a file: capture.complex16. The file name tells us this is a captured radio signal using 16 bytes foir I/Q data (https://github.com/jopohl/urh/wiki/Supported-signal-file-formats). Therefore we're going to use the excellent and intuitive tool URHhttps://github.com/jopohl/urh?tab=readme-ov-file to analyse the data, and hopefully extract a flag.
First off, we download and open URH:
pipx install urh
We then load the capture.complex16 file, and see ... err nothing? Taking a closer look at the file formats supported, it looks like URH relies on the file extension to guess the file type, since it imports raw binary data with no headers etc.
We copy the file to 2 files for the 16bit format: complex.caputure16s / complex.caputure16u, and open these:
-
.caputure16ushows a signal, but it doesn't look like a proper spectrum and URH complains it cannot understand it -
.caputure16sactually looks much more like what we expect, and URH instantly is able to understand it. So it must be this one.
The first thing we see is the Spectrogram view. This shows a view of the strength of each frequency over time, as a visualisation of the RF spectrum. We can see distinct "bursts" of traffic, we will call these "packets", which we will hypothesize contain a number of "symbols" (1's / 0's), and we can see our data is contained in a single band.
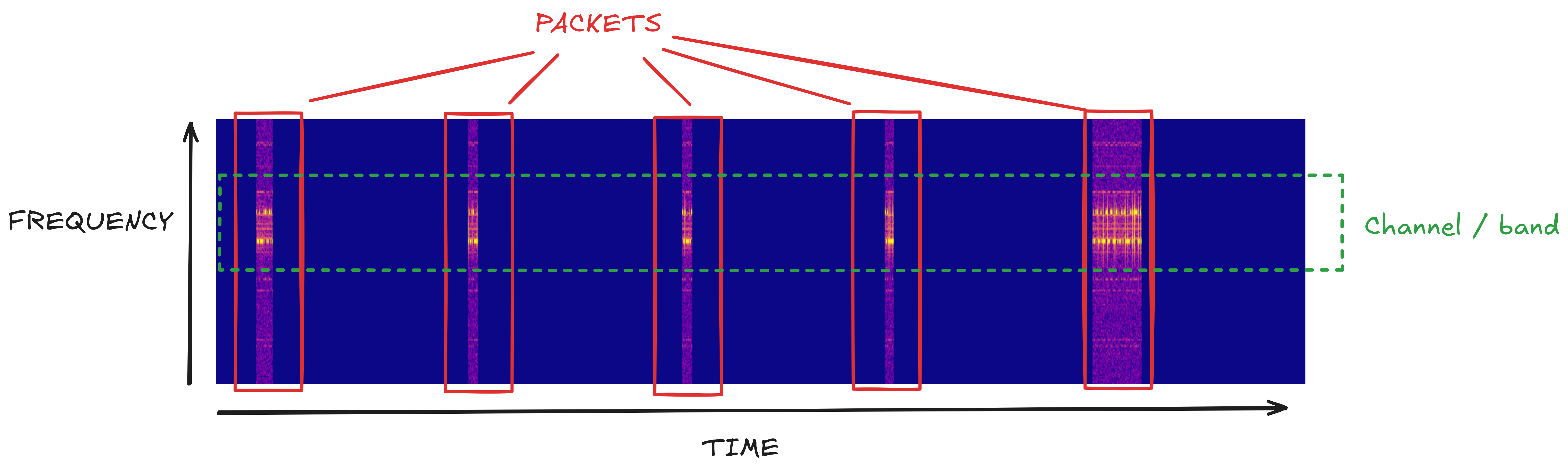
URH also tells us the length of the conversation is 14 seconds, although this isn't hugely helpful here. If we look at the number of symbols within the timespan (you can just make them out as dark and light bars within each packet shown above) it tells us the thing encoding / decoding this signal is operating faster than a human could feasibly process: we are not dealing with human created morse code, typed out by hand, but with a digital system meant to be sent and processed by a computer.

First off we highlight just the frequency range we're interested in in URH, and select "Apply bandpass filter" from the right click menu. This crops the data to only these frequencies, like cropping the images of an image. Removing the redundant background noise helps later analysis and makes the image clearer. We also adjust the Data_min and Data_max values in URH to make the visualisation clearer.
Demodulation
So the first step is to Demodulate the signal, ie recover 1's and 0's from the sine wave. URH in fact is pretty good at this for basic modulations such as ASK and FSK, and can do it automatically, but we'll just verify it manually.
First off we zoom in on a packet in the spectrogram view:
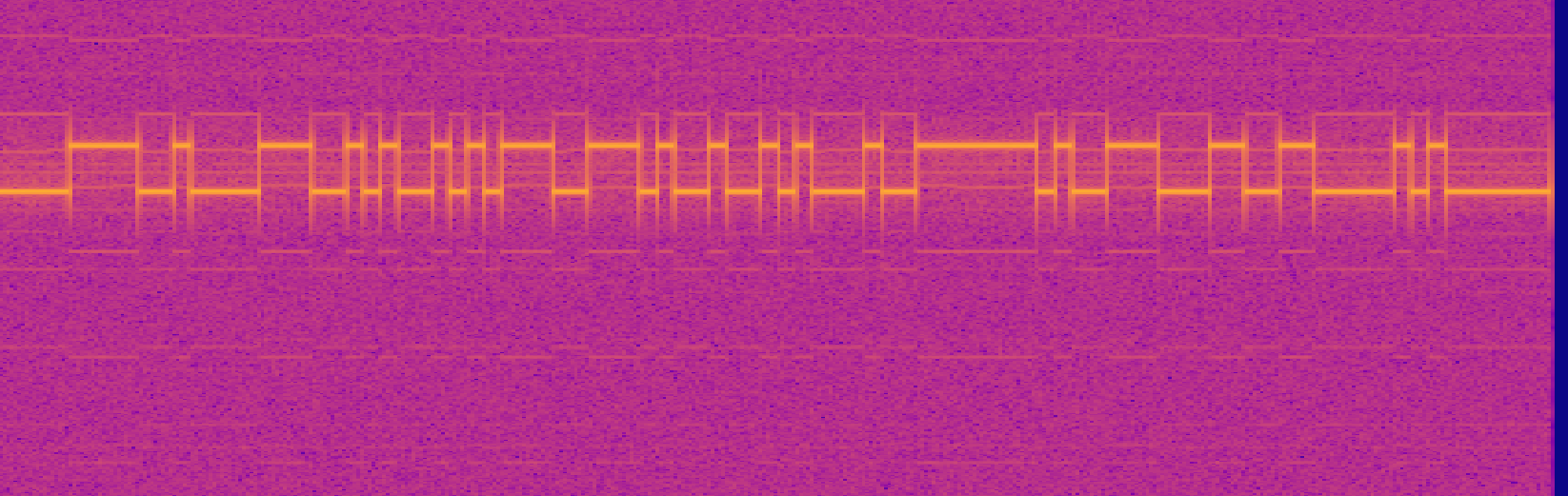
We can see here that the signal is switching between 2 distinct frequencies:

If we switch to the Analogue view in URH, we can see amplitude vs time, which confirms that the frequency is changing over time within the signal. The darker sections have more wavelengths per unit of time, and are therefore higher frequency, while the lighter sections are lower:
Since we can observe the frequency switching between 2 distinct values (and not a continuous range of values) we will deduce this is a form of digital information (ie 1's and 0's) and that the modulation is Frequency Shift Keying (FSK). In URH we can now switch the modulation type to FSK, and move to the "Demodulated view" which shows us how to interpret the data. We drag the centre line between the clear ridges, and this is how we determine each "bit" of data. If the frequency is above the centre it is a 1, and if it is below it is a 0. We can invert these later if we want, when doing further decoding, but for the time being we only care about separating the 1's from the 0's. We can tell this is the correct decoding, as there is a clear separation between the peaks and troughs:
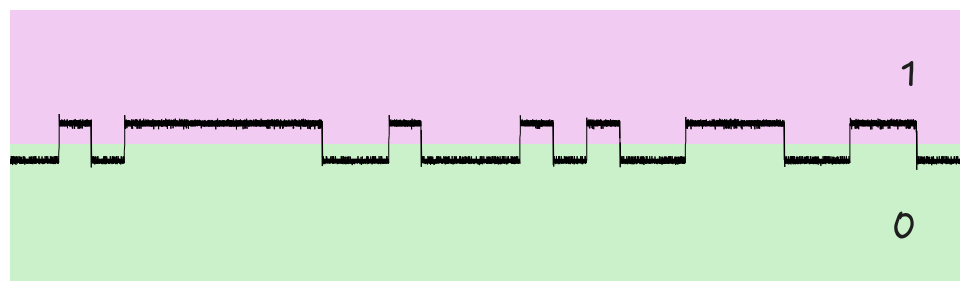
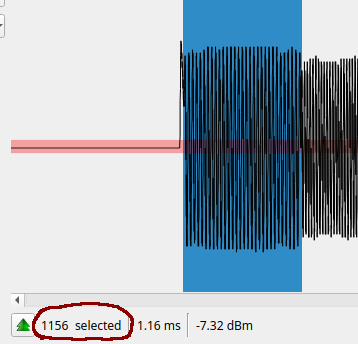
We can see that the various peaks and troughs differ in length. We usually interpret this as being repeated symbols, ie 11 would be represented as a peak twice as wide as a 1 by itself. To fully demodulate the data we need to work out the length of each individual symbol. Luckily URH does this for us, and guesses 1200, which turns out to be right. But we can also do it ourselves. Typically we look for the greatest common denominator of the various lengths represented, and smallest individual peak / trough. Here, if we select a small bump, URH tells us that it is ~ 1200 samples long. If we select a few other peaks / torughs at random we can see they are all multiples of 1200 (2400, 4800). This gives a good level of confidence that the width of each symbol is 1200 samples long.
If we take a closer look at both this demodulated view, and the original spectrogram, we can see some interesting properties of the underlying radio signal:
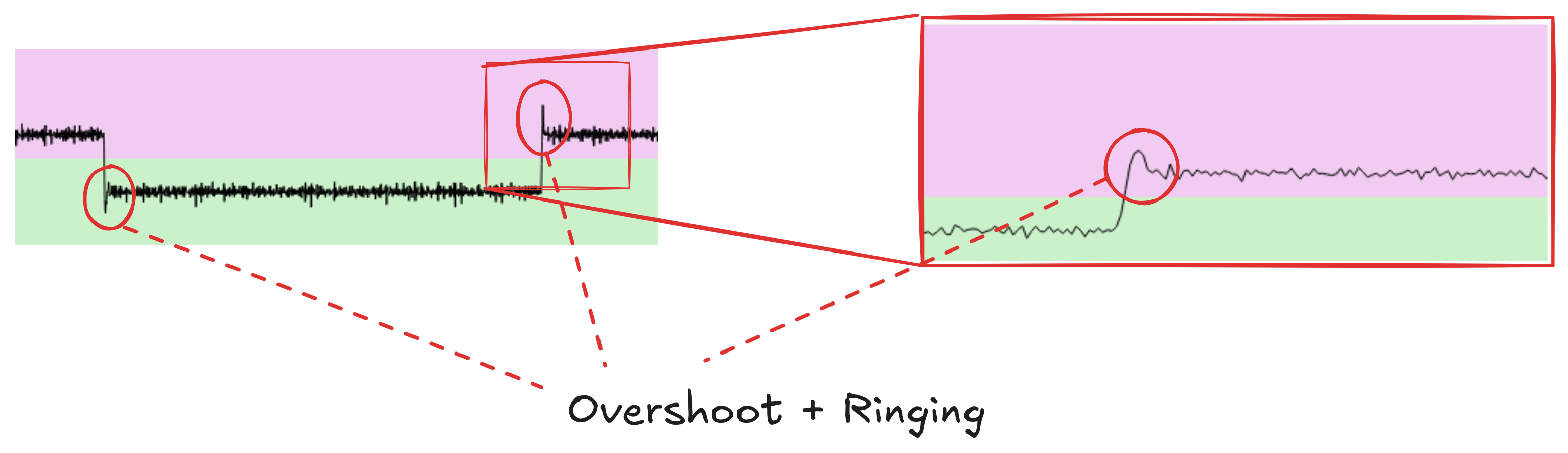
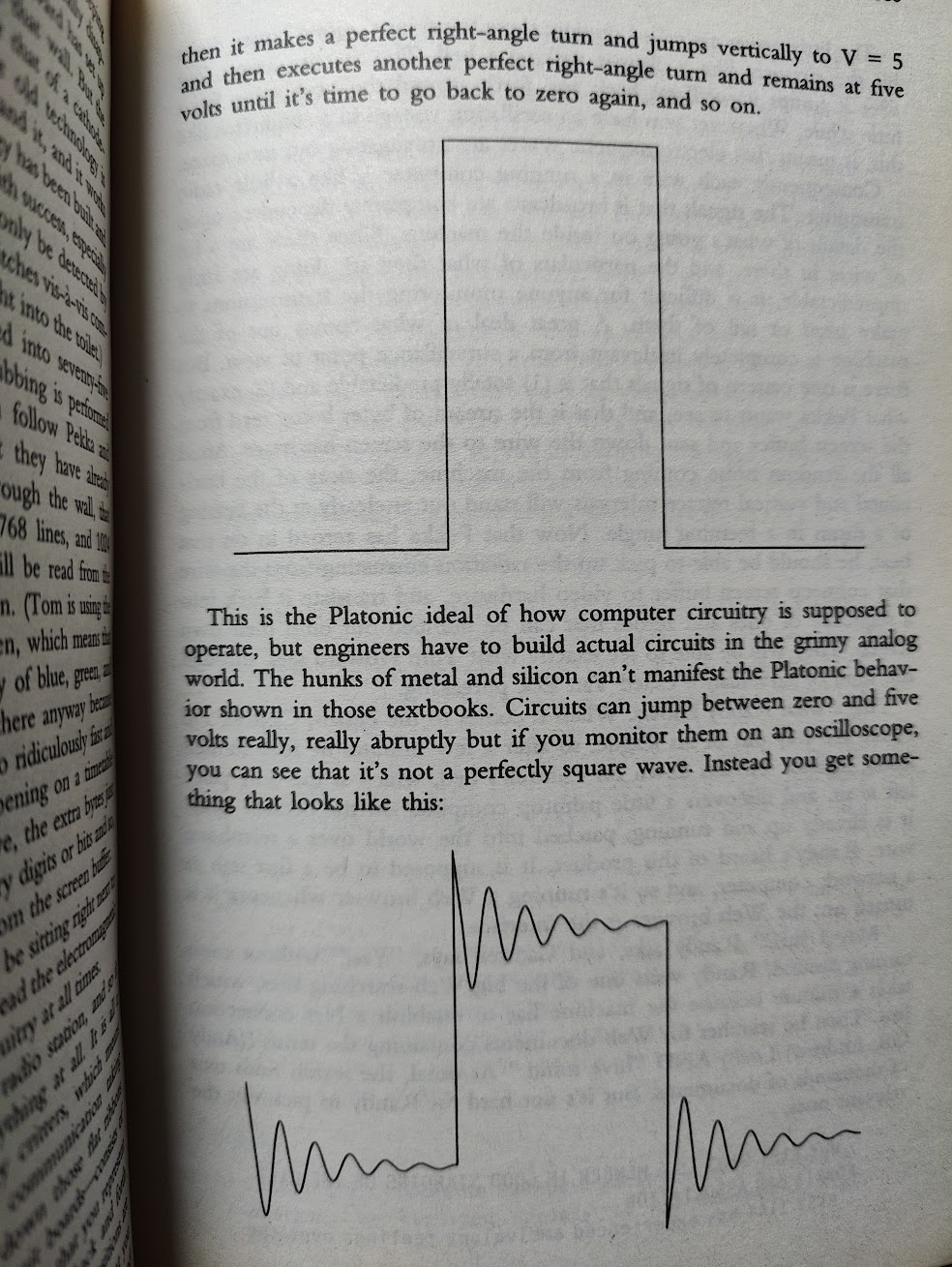
At each "Square" wave, we see a spike, that calms down to a more stable frequency, these are "overshoot" and "ringing" signals, https://en.wikipedia.org/wiki/Ringing_(signal), as described in CRYPTONOMICON's illustration of Van Eck phreaking:
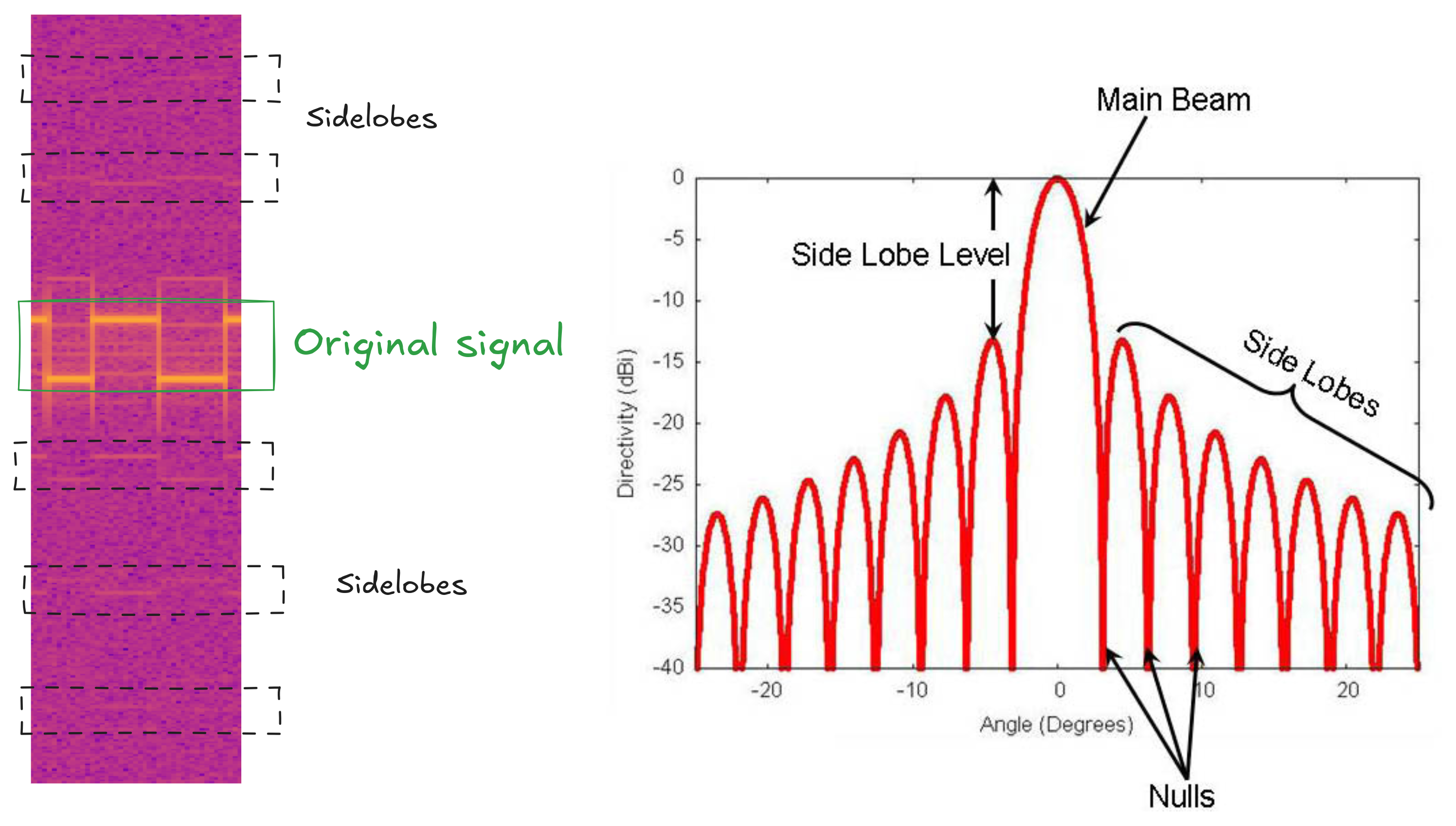
We can also see radiating "echoes" of the original frequencies, diminishing in strength the further from the carrier frequency. These are SIDELOBES, generated as an artifact of antenna mechanics (https://en.wikipedia.org/wiki/Sidelobes):
These give us a strong indication this signal was generated from an actual capture, and not synthetically generated
Decoding
Now we think we've worked out how to convert the wave to 1's and 0's by demodulating it, let's take a look at retrieving actual information from the bits, ie decoding. Given our demodulation parameters: FSK with a centre frequency of 0.015 and a samples/symbol of 1200, we get the following bits for each message:
011110000111100001000001011111100100010100111001100000000000000011110010000
111001010010101110011101001001010001001111111010011100011001100000101000000
[Pause: 2080068 samples]
011110000111100001000001011111100100010100111001100000001000000000000000001
1010110000
[Pause: 2174415 samples]
011110000111100001000001011111100100010100111001100000010000000101010110001
01000001101011010
[Pause: 2049324 samples]
011110000111100001000001011111100100010100111001100000011000000000000001010
11001100
[Pause: 2115700 samples]
000001111000011110000100000101111110010001010011100110000010000000010101000
000111000000011001101010000000101100000001101001111110011100100010110101000
111011101111101101110000111111000110110110010101101001001010011101010010000
100001111101101110000000001001110111101001111010100100111001101101000110110
001110010110101100111100000000111110011111100010100111001100001010101100000
1110011000100101111101011101111100011011100001110100100000000
[Pause: 3539490 samples]
Here again in hexadecimal:
7878417e45398000f21ca573a4a27f4e330500
[Pause: 2080029 samples]
7878417e45398080003580
[Pause: 2174377 samples]
7878417e45398101562835a
[Pause: 2049300 samples]
7878417e4539818001598
[Pause: 2115661 samples]
07878417e4539820150380cd40580d3f3916a3bbedc3f1b656929d4843edc013bd3d49cda3639
6b3c03e7e29cc2ac1cc4bebbe370e90000
[Pause: 3539490 samples]
And here in ASCII (printable chars only):
xxA~E9���s��N3%
xxA~E9��5�%
xxA~E9�V(5� (LSB padded with 0)
?9�����V��HC���=Iͣc���>~)�*��K�7�%
So far, so meaningless. If we were hoping this would nicely translate to human readable text we were wrong. First off, let's dump this into Cyberchef, using the binary representation and us a recipe From Binary > Brute force text encoding (decode)Cyberchef recipe link: https://gchq.github.io/CyberChef/#recipe=From_Binary(Space,8)Text_Encoding_Brute_Force(Encode)&input=MDExMTEwMDAwMTExMTAwMDAxMDAwMDAxMDExMTExMTAwMTAwMDEwMTAwMTExMDAxMTAwMDAwMDAwMDAwMDAwMDExMTEwMDEwMDAwMTExMDAxMDEwMDEwMTAxMTEwMDExMTAxMDAxMDAxMDEwMDAxMDAxMTExMTExMDEwMDExMTAwMDExMDAxMTAwMDAwMTAxMDAwMDAw&oeol=NEL . This will show us a table of the messages decoded using a variety of text encodings, which helps identify any unusual encodings. We also run this with a bit length of 7 and 8, to account for different character lengths. We can also try inserting a "swap endianness" block, to check both LSB and MSB, as radios / networks often work with either. Nothing massively helpful comes out of this, if we were hoping a flag would jump out at us, all the potential decodings include seemingly random non-printable characters.
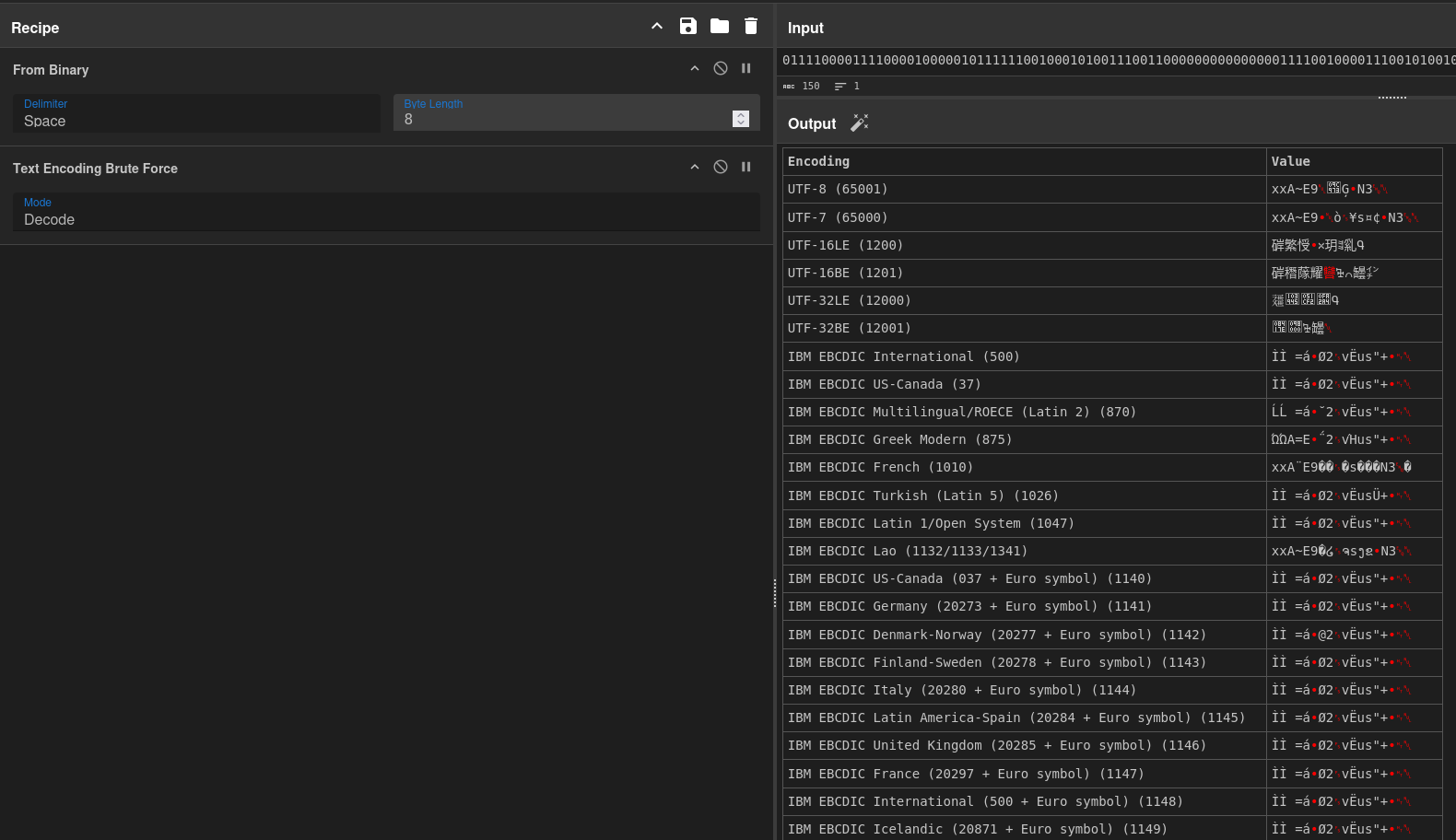
The only clear pattern we can make out is that the first 4 messages begin with the binary/ hexadecimal string:
Binary: 0111100001111000010000010111111001000101001110011000000
Hexadecimal: 7878417e45398
Which decodes in ASCII to xxA~E9, which has no obvious meaning.
This is 55 bits long, an odd length, not a multiple of 7 or 8 commonly associated with ASCII / byte encodings. it is divisible by 5, which is the symbol length of the original Baudot encoding, used in telegraphs and punched tape readers https://en.wikipedia.org/wiki/Baudot_code , putting the messages into https://www.dcode.fr/baudot-code yeilds no obvious plaintext either:
A link in Wikipedia mentions the Bacon cipher, which uses groups of 5 binary symbols. A quick experiment in cyberchef also shows nothing from this.
At this point we google the string xxA~E9, in case it's a common identifier for some known radio protocol. This reveals nothing however. Another potential approach is to shave bits off the beginning of the message, efectively bitshifting the result. This is in case the protocol beings with a number of bits before beginning the 7 / 8 bit encoding scheme, which would misalign cyberchef's results. However looking at each of the various offsets between 1 and 8 reveals nothing.
If we look at the final message we see it doesn't begin with this sequence, but that the sequence is offset into the start of the message, except for the 55th bit, which is different:

This could mean the motif serves as some kind of identifier to signify the start of data, in case of glitches. This is known as a PREAMBLE.
If we look at the binary representation, a couple of things can be made out:
while offset by the first bit, we see oscillating patterns of 4: - 4 1's - 4 0's - 4 1's - 4 0's
if we take these as 8 bit symbols we have some nice and symmetrical:
without starting 0:
11110000 (240 decimal)
11110000 (240 decimal)
with starting 0:
01111000 (120 decimal, x ASCII)
01111000 (120 decimal, x ASCII)
This also means that taken from the first symbol and divided into groups of 4 or 8, the chunks are inverses:
0111
1000
0111
1000
However both these patterns only hold for the first 16 / 17 symbols, and don't explain the rest of the pattern. They do kind of feel like a preamble, since preambles often use alternating patterns of a fixed length to syncronise the bitrate, but they convey no clear meaning. They also don't really help understand the rest of the message.
URH actually has an entire dedicated tab for analysis, so lets use this:
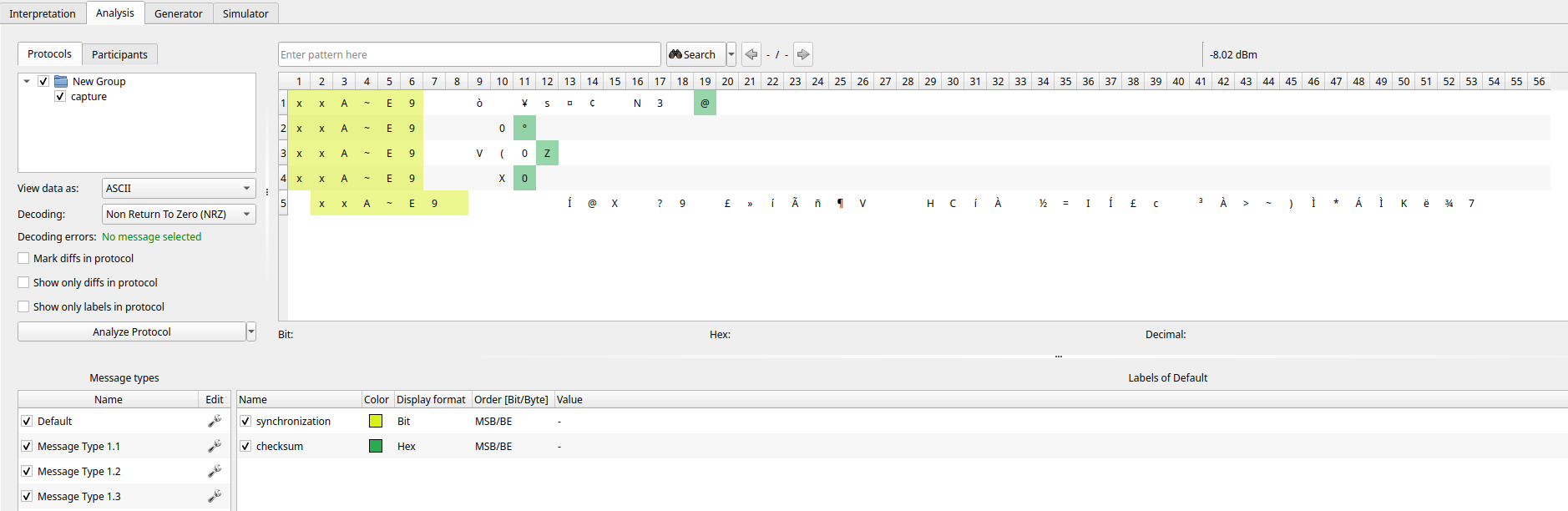
This allows us to select various decoding techniques, visualise the output, and analyse the structure of each message. Here we have selected the default Non Return to Zero (NRZ) encoding, which is just an irritating way of saying high=1, low=0, as we'd already assumed. On the right we can see that URH has auto-highlighted sections of the message and highlighted them. These highlights are the tools way of guessing what the different segments mean, and here it's guessed the same as we did: the xxA~E9 is some kind of preamble / sync word. It thinks the green blobs are checksums (checksums are usually at the end of the message), which might be the case, but we'd need to find an algorithm that makes sense. So this decoding doesn't yield results, but what about the others. I tried cycling through all the inbuilt encodings URH knew about:
- morse code
- inverse NRZ
- manchester encoding
- differential manchester encoding
But no luck. URH also allows you to create your own decodings, both using the inbuilt drag and drop architecture, or via an external program. An external program would help if I knew what the encoding scheme as, but I don't. Instead i cobble together a few basic potential encodings with the editor:
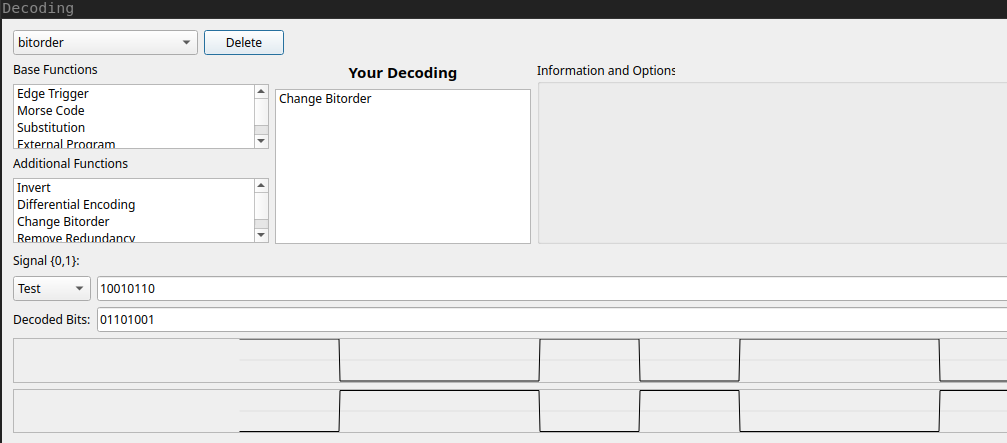
- Invert bits
- Invert endianness
- Remove data whitening
- Differential encoding
For each of these, I take the binary output and run through the earlier cyberchef recipe to detect potential text encodings for both 7 / 8 bit digits.
Still nothing.
Conclusions:
- the message is not a straightforward text encoding
Symbol analysis
Let's see if the contents of the symbols tell us something about the mesage. The characters used and their frequency can often give an interesting insight into the contents and structure of a binary message. To do this we'll generate a quick frequency histogram of characters taken from the binary decoding using Cyberchef:
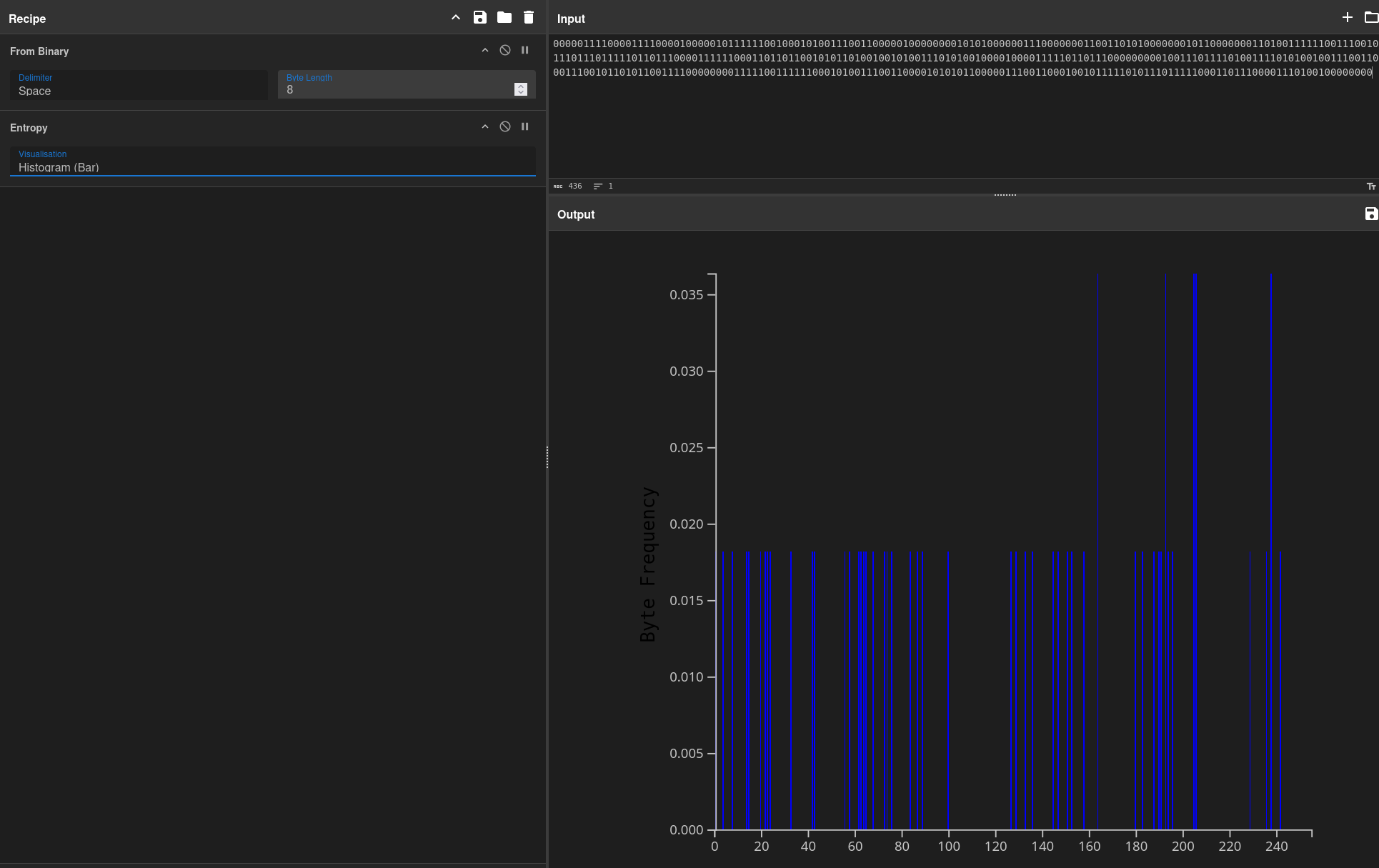
If this had resulted in a small spike of, say 26 symbols (the length of the alphabet), it would imply we were dealing with a nice and simple substitution cipher, ROT13 etc. We can also intuit those types of simple ciphers by looking for common patterns in the flag format that are echoed in the ciphertext:
However the data looks pretty much random and evenly distributed between 0 and 256, which potentially implies one of several conclusions:
- The data is encrypted, as encryption algorthims are often engineered to produce data indistinuishable from random streams
- The data is encoded / compressed: compression algorithms will seek to make full use of the available symbol alphabet, obscuring frequency patterns in the original data
However with this short a signal, we are unlikely to be able to draw many conclusions from this: frequency analysis is only effective on sufficiently long texts for patterns to emerge, and relative frequencies to be realised. Compression seems redundant for messages this short, but as this is a CTF we'll briefly explore the hypothesis that the data is encrypted.
We've already established that we don't think it's an encryption form based on substitution cipher, due to the entropy of the data, and lack of repeated patterns in the ASCII. One common form of simple encryption, used in insecure protocols and commonly seen in CTFs is XOR. XOR encryption would result in output characters across the 8-bit range (0-256) as we appear to be seeing here.
If the encryption used was XOR: the repeated pattern of xxA~E9 could be an artifact of XOR encryption using a key against a pre-amble consisting of 0's, a form of "known plaintext" attack against XOR. Trying this in cyberchef reveals no meaningful data however. A couple of other quick and dirty checks for XOR encryption:
- XOR brute force (key len 1): nothing
- XOR brute force (key len >1 with crib: disobey: nothing
At this point, we are likely over-complicating things, and should fall back on occams razor: "other things being equal, simpler explanations are generally better than more complex ones". We've begun to make too many assumptions, assuming the message is encrypted, assuming the form of the encryption (e.g XOR), and then beginning to assume the key length and the plaintext format.
This is the NSA's first law of cryptanalysis: look for plaintext.
In fact the simplest explanation for the xxA~E9 preamble is that it is simply a preamble, and not any form of leaked XOR key, and we should fall back to this line of thought before beginning to engage in fanciful explorations of cryptography.
Conclusions:
- Until we find evidence, the signal is unlikely to be encrypted or compressed
ASK??
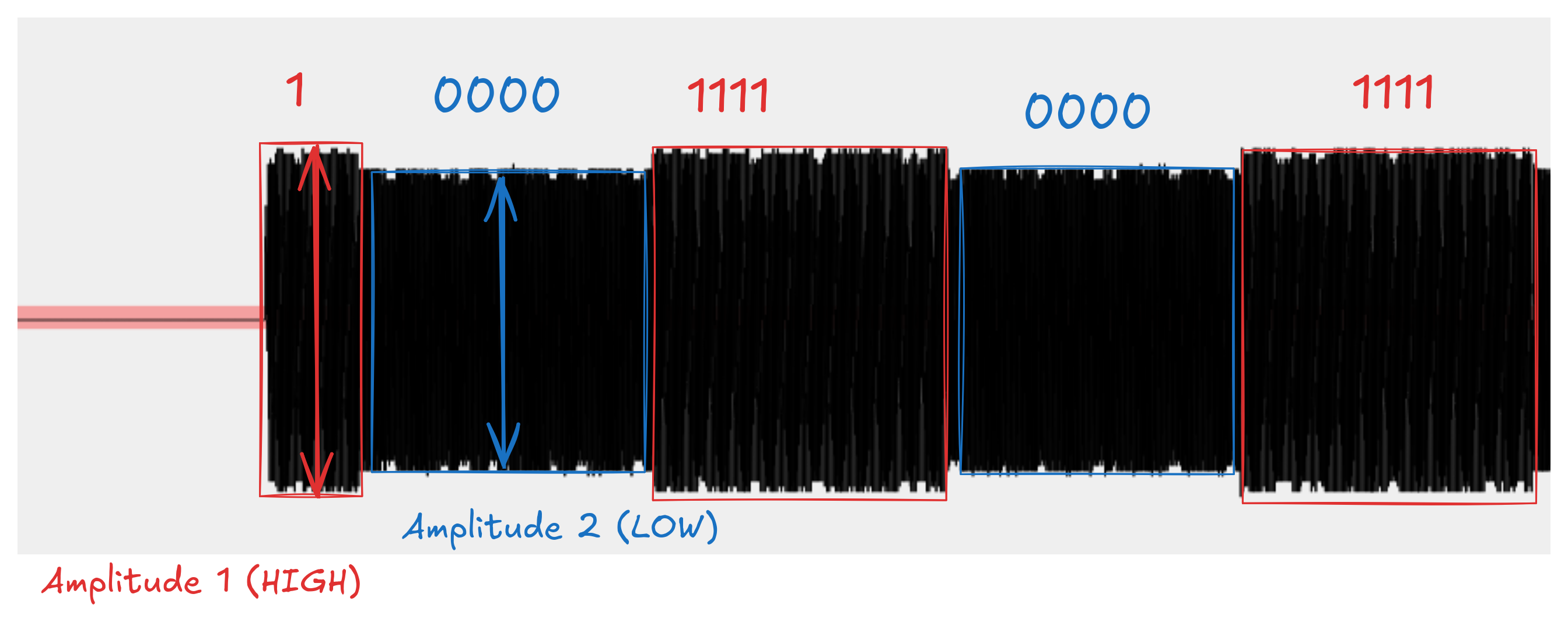
Near the beginning of the challenge, we noticed the signal appeared to be modulated in the frequency domain (ie, using FSK). But was that an assumption we should have proceeded with? Let's quickly double check whether the signal could in fact be modulated in the Amplitude domain, ie, using ASK.
If we examine the analog signal, we can in fact see slight differences in amplitude; these could be artefacts of ASK modulation
However, if we actually look closer at the signal we can see 2 reasons this doesn't quite make sense:
- The differences in amplitude are too small to be discernable amongst the noise: we would expect much more distinct peaks and troughs
- The differences in amplitude actually align with the changes in frequency, and don't appear to convey any extra information
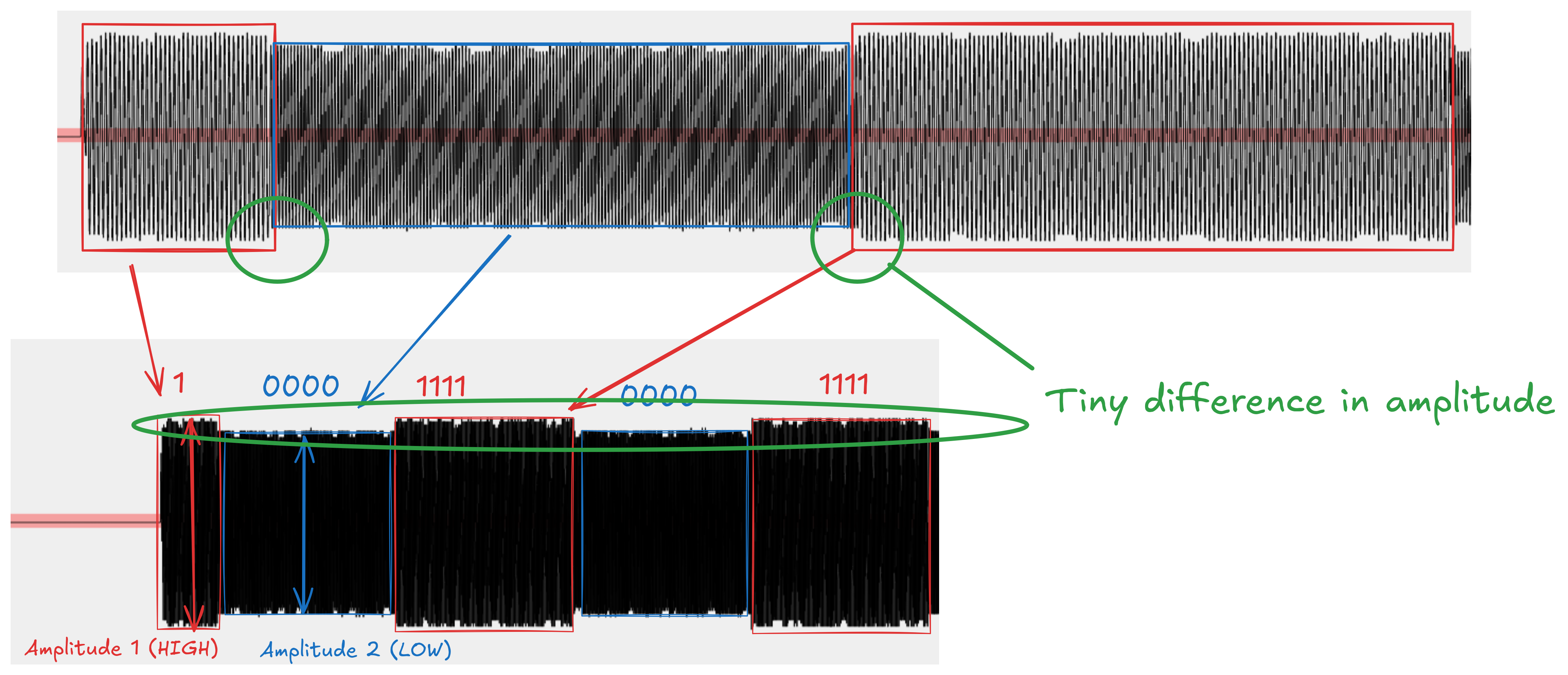
Conclusion:
- the signal is not ASK
Signal lengths
Another point about the signals we haven't examined is the length of each message: for ease of processing radio signals will often be sent in "packets" of predictable lengths, to help the receiver distinguish individual messages in a potentially noisy channel. If we look at the bit lengths of our messages we see the following:
| Message 1 | 150 bits |
|---|---|
| Message 2 | 85 bits |
| Message 3 | 92 bits |
| Message 4 | 83 bits |
| Message 5 | 436 bits |
A couple of observations here:
-
The messages are not all the same length, as a very rough estimate we have:
- 1 medium (msg1 = 150)
- 3 short (msg2, msg3, msg4 ~= 86)
- 1 long (msg5 = 436)
-
The fifth and final message is significantly longer than the others. One interpretation of this is that packets 1-4 are some handshake, and the fifth contains the data payload:
- short messages are usually used to convey signalling data (think like TCP SYN/ACK/SYNACK meta packets)
- long messages are often associated with the actual transmission of data
Therefore the fifth packet is most likely where our data (flag) is, as it is longer than the others, and long enough to contain a flag, although this is an assumption.
- There is no common denominator between all lengths (83 is a prime). This has multiple explanations:
- minor glitches in the signal have resulted in incorrect demodulation, throwing off some messages length by 1 or 2
- packets do not represent compositions of even-length symbols. For example, if all our packets could be decoded to ASCII, we would expect them to all be multiples of 7 / 8. If messages were AES encrypted, we could expect them to roughly align with the blocksize of AES, and if Baudot code, 5 bits.
Participants
Radio communications can either be unidirectional (ie broadcast), whereby a single party distributes information to a large number of potential receivers (e.g television), or a bi-directional communication between 2 or more parties. In other words, a given signal can represent information from A-> B, or from both A->B, and B-> A. In fact radio signals can even represent communications between much larger numbers of participants (https://en.wikipedia.org/wiki/Channel_access_method).
It might be relevant to the challenge to understand if we're looking at the messages between multiple parties, or listening to a solitary ALICE screaming into the void. For example if we're looking at 2 parties, we might want to see if we can distinguish some form of key-exchange happening that results in later messages being encrypted.
Let's attempt to work out if the traffic we're examining belongs to one or more parties*.
- of course, we could simply be observing one half of a bi-drectional converstation, with our capture cropped to only one side of the conversation
Multi-party comms
First off, we are going to discard the idea that our signal could be a conversation between multiple parties, for the following reasons:
- the number of packets (5) is too few
- the length of packets is too short
- the aforementioned "Occam's razor": we shouldn't assume too much complexity, trying to discern a mesh network for a simple CTF challenge is getting a little silly
Why the number of packets is relevant: We only have 5 packets: a meaningful conversation between >2 parties is likely going to be significantly more involved than this, as the total number of packets would be divided somehow between the number of parties present. On the other hand 5 signals could reasonably represent a short but meaningful exchange between 2 parties:
- Hi I'm ALICE
- Hi ALICE, I'm BOB
- Nice to meet you BOB, do you want a FLAG?
- Yes please ALICE, send that over
- Sure thing BOB: here's the FLAG: FLAG{askjdhakdhhasd}
Why The length of messages is relevant:
When you recieve a radio message for a multi-party communication, you have to work out who it is to / from. For a bi-party channel this could be simply represented with a single bit: 0 to represent ALICE and 1 to represent BOB. However when you have more participants, and especially when you have a communication medium with an unknown and potentially high number of parties, the process of establishing who is who, and who the message is meant for, begins to take substantially more bits.
As an example of this let's take Wi-Fi: https://community.cisco.com/t5/wireless-mobility-knowledge-base/802-11-frames-a-starter-guide-to-learn-wireless-sniffer-traces/ta-p/3110019.
Wi-Fi networks are designed to support large numbers of devices all communicating on the same frequency. As a result each Wi-Fi packet needs to include headers / footers with the following properties:
- who the sender is
- who the destination is
- various sequence numbers / checksums to avoid confusion when messages interfere / are descynchronised
As you can see in a Wi-Fi packet header this takes up a significant amount of data, purely for the header. In fact a Wi-Fi header by itself is longer than our shortest packet (~36 bytes vs 83 bits)

Additionally, to avoid interference, the parties need to observe a strict timing pattern to avoid conflictionhttps://en.wikipedia.org/wiki/Duplex_(telecommunications)#Time-division_duplexing . This involves distributing data in short sharp bursts, with gaps between. The parties need to synchronise their communications and also issue a bunch of packets to indicate who can send data (CTS = Clear To Send: https://en.wikipedia.org/wiki/IEEE_802.11_RTS/CTS). As a result here's what a radio spectrogram of a Wi-Fi network looks like: it's much noisier and choppier than our comms, as any available time becomes filled with synchronisation signals.
Now these are all assumptions we can argue with: there are simpler multi-party protocols than Wi-Fi that don't require as much overhead. But the point remains that if we were looking at a capture of a communications protocol between N (N>2) parties, we would expect it to be noisier, and the messages longer. So we will proceed with the assumption that our capture is of either 1 or 2 parties.
Conclusions:
- our capture does not represent communications between more than 2 participants
figuring out how many participants: signal strength
According to laws of physics, signal strength of radio communications decreases with distance exponentiallyhttps://en.wikipedia.org/wiki/Attenuation . This means that if we record a radio signal that represents a multi-party communication, messages belonging to different parties may have different average strengths (amplitudes).
Think about if you are stood between 2 people yelling at each other from a long distance away: if you are stood next to one, and far from the other you will hear one very loud voice, and one quieter. Therefore, even if you could not recognise the distinct voices of the participants, you could make a good guess that you are hearing a conversation between 2 parties, simply from the fact you can make out 2 distinct volumes.
We can apply this principle to radio analysis in the same way. A captured radio signal has to be captured from somewhereerr actually we could be looking at a purely synthetic / simulated signal generated in software, or drawn on graph paper. But if we look at the ringing, sidelobes etc we showed earlier, it seems likely this is a real signal capture . So depending on where the signal was captured, our interception point will have a distance between each side of the conversation, shown in the below image:
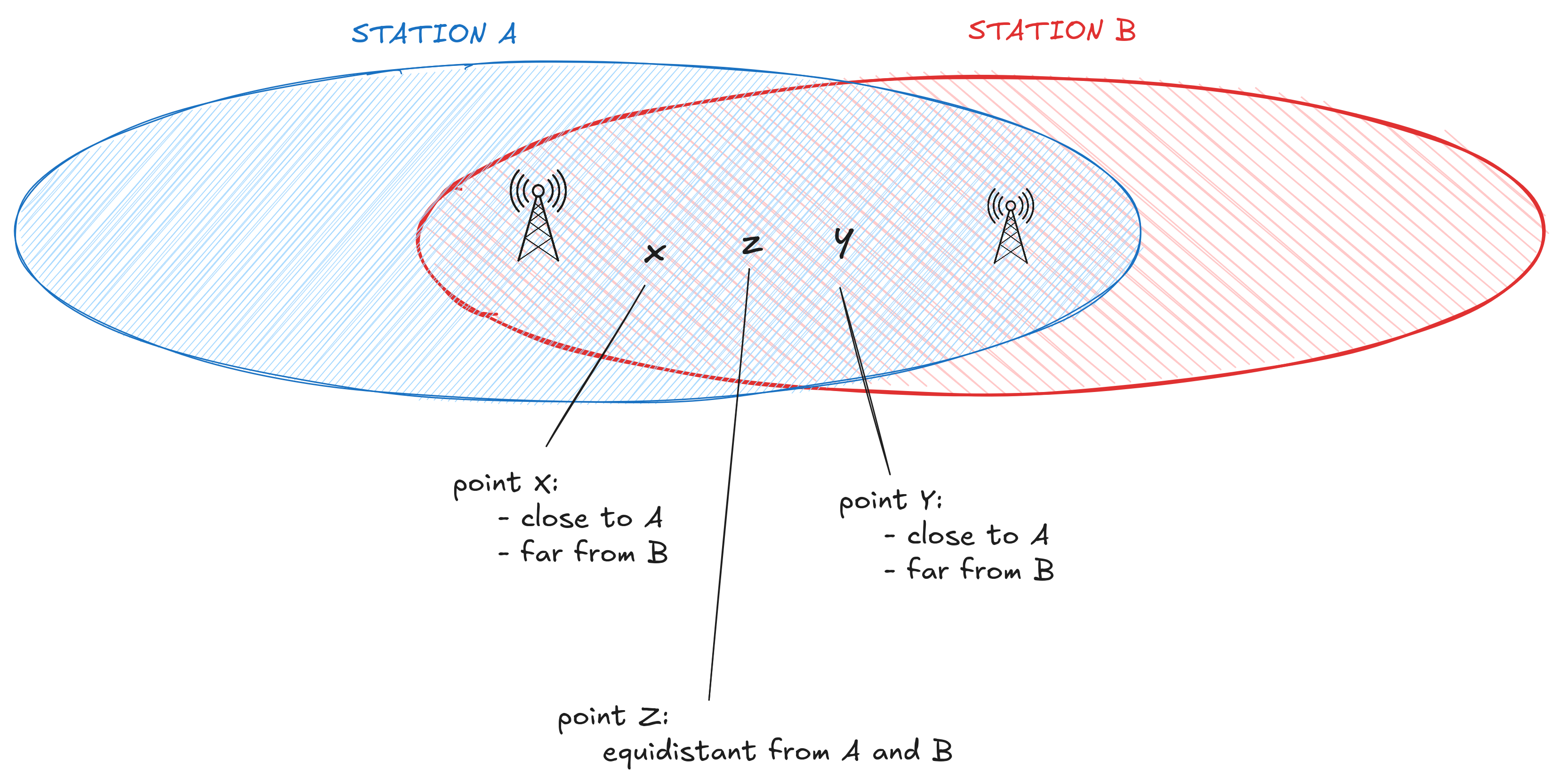
Unless we are at point Z: equidistant from either party, then one party will be stronger, and the other weaker. If we are at X, we will observe A as the stronger signal, and vice versa if we are point Y.
Now in fact, we don't just consider points on a straight line, antennas broadcast signals in multiple directions, depending on antenna construction. We can think of a distance from a signal being represented by a radius around the transmitter, and the relative signal strengths represented in 2 dimensions, in a kind of venn diagram. This can be taken further with 3 signals, used for triangulation, as in GPS or radio direction finding (GPS / DF / CRYPTO: https://www.cryptomuseum.com/df/df.htm)
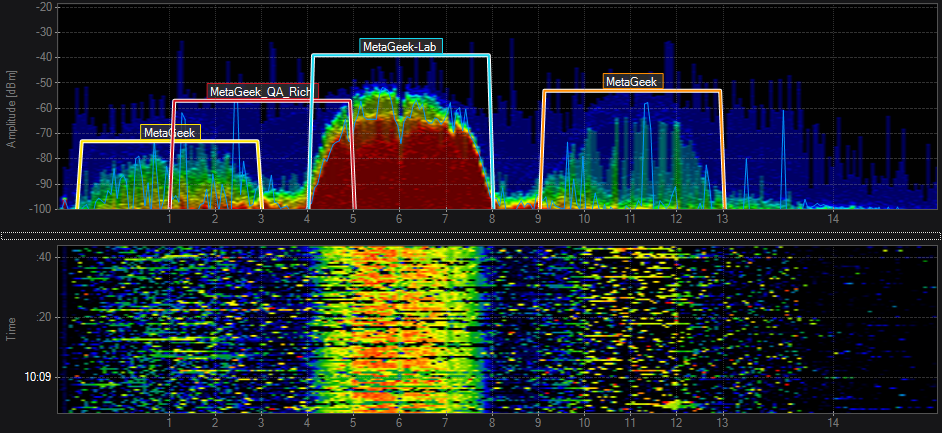
Anyway, let's put this principle in practice. If we are looking at comms between 2 parties, we may be able to determine who each is, by looking at the amplitude of each packet. An example capture that shows distinct amplitudes belonging to multiple participants is shown below:
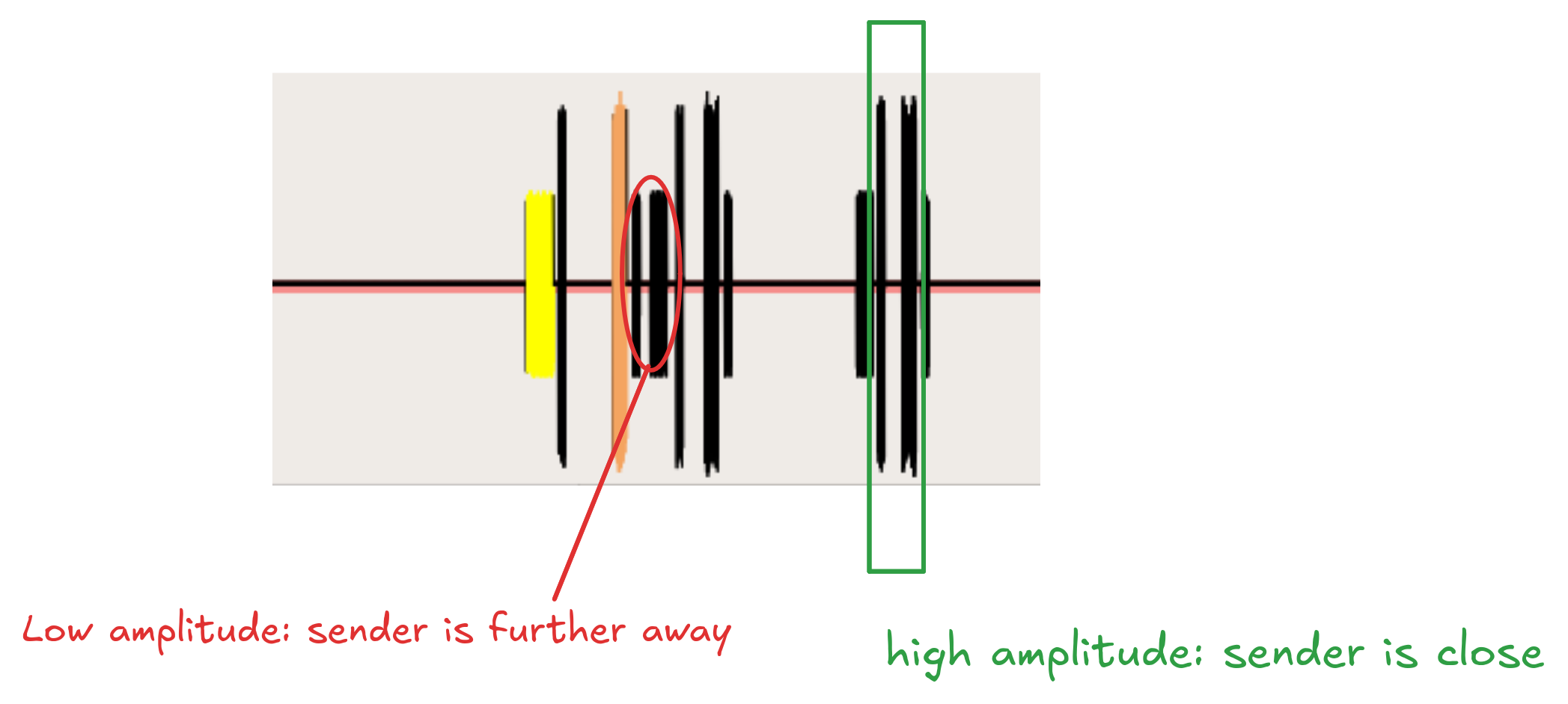
Do we see this when looking at our capture??

- not really: there's no massively discernible difference in strenght between packets
- because of the exponential drop off in signal strength, we'd expect even a relatively small difference in distance to result in discernably different amplitudes
- If we actviate URH's auto "participant detection", it also doesn't distinguish relative RSSI's of different packets
Conclusions: Either - our capture source is perfectly equidistant between both parties - our capture source is close enough to both parties there is no discernible stength difference - we are only seeing communications from a single party - the captured signal has been artificially edited to make both parties equally strong (sometimes used to make decoding easier in a noisy channel for modulations that are not ASK)
Either way, it seems highly unlikely that the party a message comes from conveys any meaningful information needed to obtain the flag, as it cannot be easily discerned. We will assume it is not important.
Conclusions:
- the sender of each packet is not relevant to it's decoding
There's yet another potential complication: multi path signals. In the real world there are multiple surfaces off which radio signals are reflected before hitting the receiver.In a building, signals bounce off walls (explaining odd patches of wifi strength / weakness in houses), and outside, tunnels, mountains, clouds, and layers of the ionosphere all reflect different signals. The degree of reflection is proportionate to the frequency / characteristics of the signal, but the resulting effect is that if you take a single signal and broadcast it, the waves will be scattered by the different objects they encounter. This creates multiple paths from source to destination, and the reciever will likely recieve the signal multiple times at different strengths and at different times. This is the same principle of shouting "ECHO" in cave or tunnel: you hear the sound reflected back at different intervals, representing the multiple lengths that the sound wave took to be reflected back to youhttps://en.wikipedia.org/wiki/Multipath_propagation .
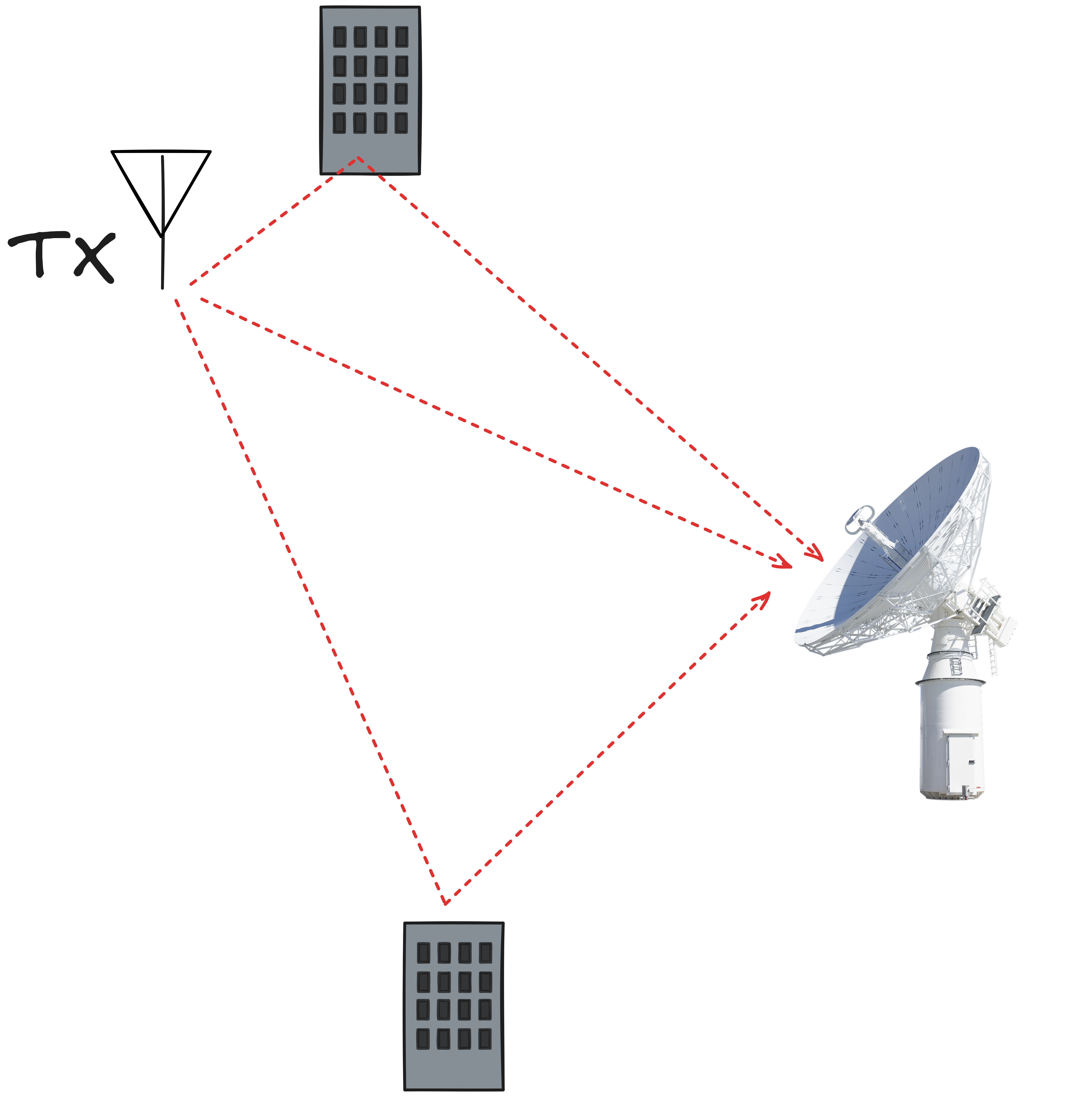
multipath reflections scatter a single signal signal across multiple routes
This reflection can even be harnessed to exchange information round corners or over the horizon, frequently used in sattelite signals / long distance communications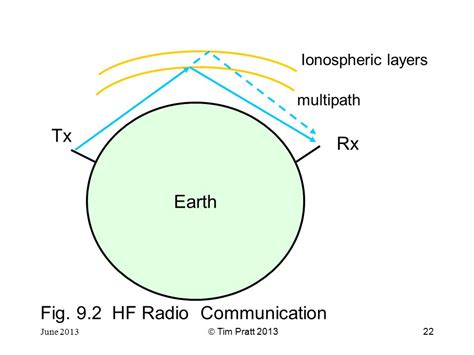
, and more recently used to generate 3D maps of structures from received radio signalshttps://ieeexplore.ieee.org/document/10025551 (not the same as systems such as SONAR, RADAR, DOPPLER RADAR, or LIDAR, which typically subtract multi-path echoes to discard noise).
Our signal doesn't appear to be complicated by this effect, so we can safely proceed and ignore it's implications.
File type analysis
CTFs like to combine different disciplines in interesting ways, so while radio's are pretty analogue maybe theres some other digital funkiness going on. A common category of CTF challenge is forensics / stegnaography: looking for hidden meaning encoded in digital files, and that's effectively what we're doing here. We have a seamingly meaningless stream of binary data, and are aiming to recover a meaningful flag from it.
Let's try that with binwalk, and the file utilitiy, to pick out any file signatures in the data. We'll do this with the first and last messages, as they have the greatest lengths.
$ echo "7878417e45398000f21ca573a4a27f4e330440" | unhex > blob5.bin
$ file blob1.bin
blob1.bin: data
$ binwalk --dd=".*" blob1.bin
DECIMAL HEXADECIMAL DESCRIPTION
--------------------------------------------------------------------------------
$ echo "07878417e4539820150380cd40580d3f3916a3bbedc3f1b656929d4843edc013bd3d49cda36396b3c03e7e29cc2ac1cc4bebbe370e9000" | unhex > blob5.bin
$ file blob5.bin
blob5.bin: data
$ binwalk --dd=".*" blob5.bin
DECIMAL HEXADECIMAL DESCRIPTION
--------------------------------------------------------------------------------
$
Neither tool finds anything.
Conclusion:
- the message does not represent an encoded file with a known filetype
Eventual analysis
I wasn't able to decode the flag or extract any meaning from the messages. If we put together our conclusions we have the following hints:
- the capture is a digital transmission, sent and received by a computer not a human
- the capture represents a real signal captured with radio hardware
- the message is not a straightforward text encoding
- the signal is not ASK
- the signal is likely to be FSK encoded, with a sample/symbol of 1200
- Until we find evidence, the signal is unlikely to be encrypted or compressed
- the sender of each packet is not relevant to it's decoding
- our capture does not represent communications between more than 2 participants
- The fifth packet is most likely where our data (flag) is
- the message does not represent an encoded file with a known filetype Either:
- minor glitches in the signal have resulted in incorrect demodulation, throwing off some messages length by 1 or 2
- packets do not represent compositions of even-length symbols.
So, in keeping with th spirit of the blog, I've failed to slve this challenge, but in the process learned a lot about radio signals and decoding, found ut about the aweome URH tool, so it's still been fun.
To be continued...
Glossary
PREAMBLE A series of symbols to indicate the start of a message / packet
Frequency: The rate at which a radio wave oscillates, typically measured in Hertz (Hz). It determines the wave's position on the electromagnetic spectrum.
Amplitude: The strength of a radio wave, representing the power or intensity of the signal.
-
Modulation: The process of varying a property of a carrier wave (e.g., amplitude, frequency, or phase) to encode information for transmission.
- ASK (Amplitude Shift Keying): A digital modulation technique where the amplitude of the carrier wave is varied to represent binary data (e.g., 0 or 1).
- FSK (Frequency Shift Keying): A digital modulation method where the frequency of the carrier wave is shifted between discrete values to represent binary data.
Channel: A specific frequency band allocated for the transmission of a signal, ensuring separation from other signals
Sidelobe: Unintended emissions of power from a signal outside its main lobe, often caused by imperfections in transmission